Waarom een Telugu-personage Apple-apparaten kapot maakt
Apple heeft enkele maanden buggy gehad. Nu hebben we een nieuwe, serieuze bug in de tekstweergavefunctionaliteit op iPhones. De bug wordt geactiveerd door een enkel Telugu-personage, waardoor een iPhone een onbreekbare opstartlus kan invoeren door een bericht met het personage te ontvangen. Laten we ingaan op de reden waarom een enkel personage zulke grote problemen kan veroorzaken met iOS.
Opmerking: een oplossing voor de Telugu-bug is beschikbaar in de meest recente versie van iOS (11.2.6). Als het Telugu-personage uw app of apparaat heeft vergrendeld, herstelt u uw iPhone via iTunes en werkt u bij naar de meest recente versie van iOS. Als uw iPhone vastzit in een opstartlus, moet u deze mogelijk in de status Device Firmware Update (DFU) zetten om iTunes te laten herkennen. Wanneer u klaar bent, herstelt u uw apparaat vanaf uw meest recente back-up, die u hopelijk hebt gemaakt.
Wat is Telugu?

Telugu is een taal die wordt gesproken en geschreven in delen van India, met name de staten Andhra Pradesh, Telangana en in de stad Yanam. Zoals veel op scripts gebaseerde talen, zoals Arabische en andere Brahmische scripts, gebruikt Telugu enkele speciale functies van de Unicode-tekenset om de karakters ervan op een computerscherm weer te geven.
Hoewel de meeste Latijnse letters worden weergegeven door één 8-bits Unicode-codepunt voor ASCII-compatibiliteit (de letter A bestaat bijvoorbeeld op het Unicode-codepunt U+0041, die in binair 01000001 wordt weergegeven door 01000001 ), zijn talen geschreven met script of niet- Latijnse letters combineren meestal meer dan één Unicode-codepunt om hun karakters weer te geven.
Dit geldt vooral voor talen, zoals Telugu, die de taalversies van letters in clusters combineren. In tegenstelling tot de stilistische ligaturen van het Engels, is de verbinding tussen elke Telugu-brief taalkundig belangrijk. Om hieraan tegemoet te komen, bevat Unicode een complex systeem van het koppelen van tekens, elk weergegeven door hun eigen codepunt, aan elkaar.
Gezien het grote aantal Unicode-codepunten, kan dit een bijna oneindige variëteit creëren. Deze punten worden gecombineerd om een leesbaar karakter te krijgen. Op deze manier heeft Unicode geen Unicode-codepunt nodig voor letterlijk alle mogelijke Telugu-woorden. In plaats daarvan combineert Unicode Telugu-medeklinkers, klinkers en diakritische tekens ("virama") samen om woorden te maken die als een enkel teken worden weergegeven. Hetzelfde geldt voor andere talen met orthografische regels voor ligaturen, zoals het Arabisch.
Wat veroorzaakt de crash?

Het probleem lijkt te zijn gerelateerd aan de Zero Width Non-Joiner (ZWNJ) op codepunt U+200C . De ZWNJ vraagt dat twee aangrenzende karakters renderen zonder hun typische ligatuur. In het Engels zorgt een ZWNJ ervoor dat de karakters niet worden afgedrukt met hun standaard verbindingsligatuur, maar in plaats daarvan elke f. Maar in combinatie met een specifieke set van vier Telugu-codepunten (die allemaal moeten worden gecombineerd tot een enkele cluster) kan iOS om de een of andere reden het resultaat niet correct weergeven.
Sommigen hebben gespeculeerd dat Apple's San Francisco-lettertype het personage niet kan weergeven, terwijl anderen hebben gezegd dat het specifieke renderingproces dat Apple gebruikt de schuld is. Wat de precieze oorzaak ook is, de poging om het personage weer te geven veroorzaakt een dramatische crash van wat het ook veroorzaakt, van Berichten en WhatsApp tot Springboard. De Unicode-codepunten waaruit het karakter bestaat ("gya" betekent "kennis") zijn hieronder:
U+0C1Cja (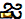 )
)U+0C4Deen virama of diakritisch teken ( )
)U+0C1Enya (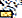 )
)U+200Cniet-U+200Ceen breedte van nulU+0C3Eaa (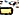 )
)
 )
) )
) )
) )
)Maar we kunnen Zero Width Non-Joiner (ZWNJ) niet alleen de schuld geven. Het wordt ook zonder enig probleem gebruikt in de onschadelijke familie-emoji's (????). Het lijkt een specifieke combinatie te zijn van een aantal specifieke codepunten en de ZWNJ. Nog erger te noemen, het lijkt erop dat de ZWNJ geen bepaald effect heeft op de weergave op dit Telugu-cluster of dat het er in de eerste plaats niet eens zou moeten zijn.
Andere brahmische scriptproblemen
Telugu is echter niet de enige taal met dit probleem. Bengali en Devanagari, die Unicode op een vergelijkbare manier gebruiken voor hun Brahmische scripts, hebben hetzelfde probleem. Manish Goregaokar schrijft een fasinerende en gedetailleerde blogpost die de exacte crashcasus nog verder breekt:
Elke reeks
in Devanagari, Bengali en Telugu, waar:1.
consonant2is suffix-join (pstf/vatu)
2.consonant1is geen herformuleringsbrief
3.vowelheeft geen twee glyph-componenten
Conclusie: Waarom werd dit niet betrapt door Apple?
Om te begrijpen hoe deze bug is doorgekomen, moet je jezelf in Apple's schoenen stoppen. Natuurlijk, deze karaktercombinatie is niet een of ander super obscuur woord in de Telugu-taal. Maar de iPhone biedt ondersteuning voor tientallen talen. Er zijn letterlijk miljarden potentiële combinaties in Unicode. Met die veelzijdigheid zouden zinvolle tests voor Unicode-bugs vóór een release reguliere software-updates in principe onmogelijk maken.
De fout had echter niet zoveel schade mogen veroorzaken. Telefoons mogen niet worden gemetseld op basis van de inhoud van een sms-bericht. Achteraf gezien is het zeker 20/20, maar het lijkt erop dat het renderen van het personage als een vraagtekenvak ( ) beter zou zijn geweest dan het crashen van Springboard.