5 Grep Tools voor Linux
Zoals elke Linux-gebruiker ongetwijfeld weet, is grep een betrouwbare command-line tool voor diepgaand zoeken naar bestanden. Toch vermijden veel beginners het omdat ze de terminal niet leuk vinden. De apps in dit artikel zijn geen exacte alternatieven voor grep, omdat grep in sommige gebruiksscenario's echt onvervangbaar is. In plaats daarvan laten we ze visuele upgrades voor grep noemen omdat ze de functionaliteit van grep uitbreiden en deze omwikkelen in een volledige grafische interface.
1. Regexxer
Regexxer is een praktische tool voor het zoeken naar bestanden waarmee u bestanden rechtstreeks vanuit de interface kunt bewerken. U kunt op naam zoeken naar bestanden en mappen en in tekstbestanden (inclusief HTML- en XML-bestanden) kijken. Aan de linkerkant van het venster kunt u de doelmap en het patroon selecteren (zet * voor alle bestanden of * .txt alleen voor tekstbestanden). Regexxer kan recursief zoeken in submappen van een geselecteerde map en verborgen bestanden opnemen in de resultaten.
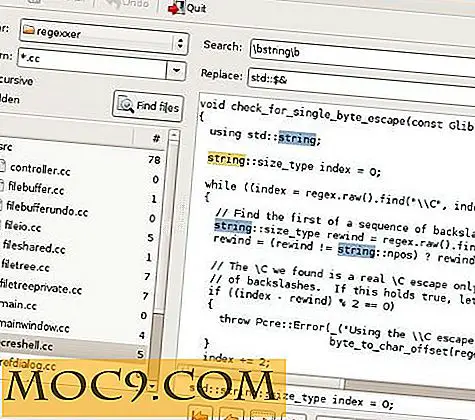
Aan de rechterkant van het venster kunt u "zoeken en vervangen" uitvoeren op een geselecteerd bestand. Hier kunt u slechts één exemplaar van een gevonden woordgroep of allemaal automatisch vervangen. U kunt ook de geselecteerde frase in alle gevonden bestanden vervangen, wat handig is voor batchbewerking.
2. Searchmonkey
Vroeger was Searchmonkey erg populair. Op een gegeven moment hield de ontwikkeling van de Linux-versie op en nu biedt de website alleen nieuwe downloads voor Windows. Toch kan de oude versie worden geïnstalleerd vanuit de opslagplaatsen van bijna elke Linux-distributie. Misschien verrassend, het werkt geweldig en het is echt snel. U kunt Searchmonkey gebruiken om bestanden en mappen op naam te vinden, of om door de inhoud te bladeren en te zoeken naar zinnen met behulp van reguliere expressies.

Met Searchmonkey kunt u complexe query's maken met de wizard Bestandsexpressie (geactiveerd door op de knop Expression Builder te klikken) en een optie met de naam Test Regular Expression (in het menu Extra's). Het kan recursief zoeken naar bestanden en u kunt de zoekdiepte instellen (naar hoeveel submappen het moet kijken) en bestanden filteren op grootte en datum. Op het tabblad "Opties" kunt u het aantal bestanden in de resultaten beperken en kiezen hoeveel contextlijnen u wilt weergeven.
3. DocFetcher
In plaats van direct uw bestandssysteem te doorzoeken, zal DocFetcher u vragen om een index te bouwen en vervolgens uw zoekopdrachten alleen in geïndexeerde bestanden te zoeken. Het biedt een draagbare versie (pak het uit en voer het .sh-bestand vanaf de terminal uit) voor zowel 32- als 64-bit-systemen. Als u een index wilt maken, klikt u met de rechtermuisknop in het gebied "Zoekbereik" aan de linkerkant.

U kunt mappen aan de index toevoegen, het maken van indexen onderbreken en later doorgaan, archiefbestanden (ZIP, TAR) indexeren als mappen en geselecteerde bestanden uitsluiten van de index met behulp van reguliere expressies.
DocFetcher heeft een ingebouwde HTML-renderer waarmee u HTML-bestanden kunt bekijken, compleet met opmaak en afbeeldingen. Het biedt een privacy-bewuste optie om de zoekgeschiedenis te verwijderen en kunt u zoeken naar en in bestanden met behulp van jokertekens, Booleaanse operatoren, fuzzy zoeken (vindt vergelijkbare woorden), nabijheid zoeken (hoever de woorden in tekst van elkaar moeten zijn), en meer. DocFetcher ondersteunt een indrukwekkend aantal indelingen, waaronder Microsoft- en Libre Office-bestanden (DOC, DOCX, ODT, OTP ...), PDF en EPUB, HTML en XML, Outlook PST-e-mailbestanden en metadata voor audio en afbeeldingen.
4. Herwin
Regain is een zoekmachine voor uw bureaublad; zoiets als Google, maar dan voor je bestanden en mappen. Het is geschreven in Java, dus het werkt op Linux, OS X en Windows, op voorwaarde dat je Java correct hebt geïnstalleerd en geconfigureerd. Het installatiebestand is beschikbaar op de projectwebsite en u kunt het eenvoudig in een map uitpakken, die map in de terminal openen en java -jar regain.jar om de toepassing te starten. (Het bestand "regain.jar" moet uitvoerbaar zijn). Regain wordt uitgevoerd in uw standaardwebbrowser.

Als u naar uw bestanden en mappen wilt zoeken, moet Regain eerst uw systeem crawlen en een zoekindex maken. In het formulier "Voorkeuren" voegt u de mappen toe die u wilt indexeren. Als u bepaalde bestanden niet in de index wilt opnemen, plaatst u ze op een zwarte lijst in het bestand "CrawlerConfiguration.xml". Zodra u Regain begint te gebruiken, zal het de index doorzoeken in plaats van de volledige harde schijf te scannen. Dit bespaart systeembronnen en maakt zoeken sneller.
5. PDFgrep
Van alle tools in deze lijst is PDFgrep het meest vergelijkbaar met de oorspronkelijke grep, maar het is ook "de vreemde eend in de bijt", omdat het een opdrachtregelprogramma is. Verschillende distributies bieden PDFgrep aan in hun repositories, maar de nieuwste versie (momenteel 1.3.2) moet worden gecompileerd.
Terwijl grep het regelnummer uitvoert waarin de zoekreeks verschijnt, toont PDFgrep in plaats daarvan het paginanummer. Dit is nuttiger voor PDF-bestanden omdat we ze als boeken lezen en niet regel voor regel analyseren. PDFgrep werkt alleen in PDF-bestanden. Ze moeten worden geconverteerd van tekst of OCR-ed, niet alleen gescande afbeeldingen.

Als u naar een woord in een PDF-bestand wilt zoeken, typt u:
pdfgrep word filename.pdf
Om de zaak te negeren, gebruikt u de optie -i :
pdfgrep -i woord bestandsnaam.pdf
Dit zal "Woord", "woord", "WOORD" en andere mogelijke combinaties vinden. Als u op zoek bent naar een zin, moet u deze tussen aanhalingstekens plaatsen. Enkele handige opties zijn:
-n: voert het paginanummer uit voor elke match-c: drukt alleen het aantal overeenkomsten in een bestand af-ptoont het aantal overeenkomsten per pagina-C NUMBER: drukt het geselecteerde aantal tekens rond elke overeenkomst af voor context. In plaats van een cijfer kunt u "lijn" schrijven en PDFgrep zal de hele regel afdrukken.
PDFgrep kan recursief zoeken in alle submappen van een actieve map en door meerdere PDF-bestanden bladeren. Het ondersteunt ook reguliere expressies en opties kunnen worden gecombineerd:
pdfgrep -nH "Linux world" file1.pdf file2.pdf /home/user/Desktop/newfile.pdf
Hiermee worden het paginanummer en de bestandsnaam voor elke match afgedrukt (vanwege de optie -H ).
Welke Linux-tools en -opdrachten gebruik je om bestanden te vinden? Deel je favorieten in de reacties hieronder.
Afbeeldingscreditering: bron met uitgelichte afbeeldingen, bron van afbeeldingsafbeeldingen